
Objects in a SQL Server database are stored as a collection of 2K pages. This section describes how the pages for tables and indexes are organized.
The data for each table is stored in a doubly linked list of 2K data pages. Each data page has a 32-byte header containing the table object identifier, a pointer to the previous page in the data chain, a pointer to the next page in the chain, and other internal data. Data rows make up the rest of the data page after the header.
All of the page chains for tables and indexes are anchored by page pointers in the sysindexes table. Every table will have one chain of data pages, plus additional structures to implement any indexes defined for the table.
Each table and index has a row in the sysusages table uniquely identified by the combination of the object identifier (id) column and the index identifier (indid) column.
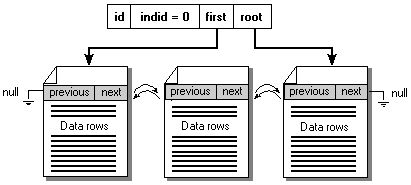
The simplest table structure is a table without indexes. This type of table has one row in sysindexes with indid = 0. The column sysindexes.first points to the first page in the data chain for the table. sysindexes.root points to the page at the end of the data chain for the table. The data chain is a doubly linked list of data pages holding the data rows for the table. The data pages and the rows within them are not stored in any specific order. All inserts simply go to the end of the data page chain.
The next step in complexity is a table with a single clustered index. This table has only one row in sysindexes, which will have indid = 1. sysindexes.first points to the first page in the data chain. The pages in the data chain and the rows within them are ordered on the value of the clustered index key. All inserts are made at the point the key value in the inserted row fits in the ordering sequence. sysindexes.root points to the top of the clustered index.
SQL Server indexes are organized as binary trees. Each page in an index holds a page header followed by index rows. Each index row contains a key value and a pointer to either a page or a data row. Each page in an index is called an index node. The top node of the binary tree is called the root node. The bottom layer of nodes in the index are called the leaf nodes. In a clustered index, the data page chain makes up the leaf nodes. Any index levels between the root and the leaves are collectively known as intermediate levels.
The following illustration shows the structure of a table with a clustered index.
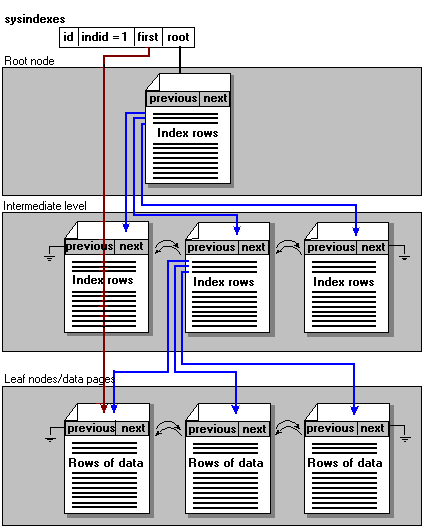
Note that the data rows are stored in sequence on their key value. sysindexes.first points to the start of the data chain; the data chain is also the leaf level of the index. The data rows in the data chain are all ordered on the indexes key. There is one intermediate level in the index. Sysindexes.root points to the root of the binary tree, and from the root node the system can navigate to any node in the structure. Each index node contains index rows that indicate the starting key value and page number of each page in the next lower level.
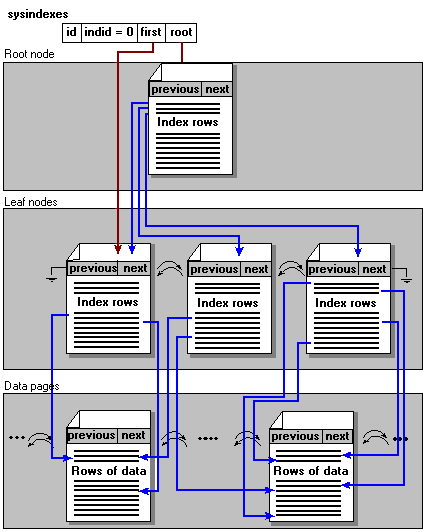
Nonclustered indexes have the same binary tree structure, but have one significant difference from clustered indexes. This is that the data rows are not stored in order on the keys of the nonclustered index. From the point of view of the nonclustered index, the data rows appear to be randomly distributed through the data pages. Because of this, the leaf layer of a nonclustered index does not consist of the data page chain. The leaf nodes instead contain index rows consisting of key values and pointers to the row (or rows if the index is also nonunique) that have that key value. Also, sysindexes.first points to the first page of the leaf layer of the index, not to the start of the data pages as in the case of a clustered index.
All indexes have a distribution page that contains distribution statistics about the current key values for that index. These statistics are used by the SQL Server optimizer to determine how effectively that index would support the query being optimized. sysindexes.distribution points to the distribution page for the associated index.
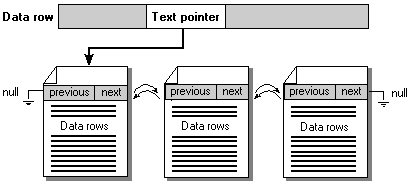
Text and image values are not stored as part of the data row but are instead stored in separate page chains of their own. For each text or image value, all that is actually stored in the data row itself is a 16-byte page pointer. For each row, this pointer points to the start of a page chain holding the text or image pages. A row containing multiple text or image columns will have one pointer and chain combination for each text or image column in the row.
The space allocations for all the text and image columns of each table are managed from one row in sysindexes, which has an indid of 255. If a table has multiple text or image columns, it will still only have one row in sysindexes with an indid of 255.
If a row containing a text or image column is inserted with a text or image value set to NULL, then no pages are allocated for that text or image chain. As soon as the row has its text or image value updated, at least one page is allocated to hold the new data value.
In the following query, even though the user specified NULL as a data value, it will still cause the allocation of a 2K text page.
UPDATE mytable SET textcol = NULL
WHERE keycol = 'somevalue'
Text and image pages can each hold 1,800 bytes of data.
The log in a SQL Server database is stored as the syslogs system table. syslogs can be thought of as simply a table with no indexes. The log pages are the data page chain of the syslogs table.