It is easiest to understand how document indexing works by following the sequence of operations that happens when a document is modified. Index Server, unlike many indexing systems, doesn't normally check for modified documents, something which burdens system resources. Rather, it registers with the file system for change notifications and updates the indexes only when appropriate.
When a document on an NTFS volume is modified, the file system notifies Index Server of the change. Index Server may not index the document right away. Indexing is a lazy process that happens in the background and only when there are sufficient computer resources available to do the indexing without adversely affecting overall system performance. When Index Server decides that it can index changes, it opens the documents and starts the indexing process.
Many index products use a polling mechanism, where every ten minutes, for example, they look at the disk for files that have been added, files that have been deleted, or files that have been modified since the last scan. This works acceptably in many circumstances, but often it doesn't scale well. Continuous polling would prevent any work from getting done. Therefore, polling is periodic, maybe every ten minutes or every hour. However, this can be painfully expensive on a very large server. This is why Index Server uses the operating system to keep track of when a file is modified.
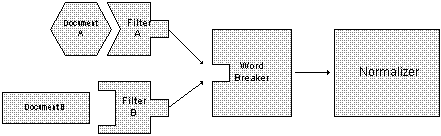
The indexing process consists of three main stages, filtering, word breaking and normalization as shown in Figure 4.
Figure 4 - Indexing Process
The first step in indexing is content filtering. Documents are typically stored in a private file format which is opaque to the system. For example, WordPerfect files are stored on the disk in a different way than Microsoft Word files. Many content indexing systems don't understand these private file formats and consequently don't index them. Index Server uses open-standard content filters to index private file formats. A content filter can be thought of as a little version of an application that only knows how to read its own files.
When the system begins operating on a document, it determines the document's type and uses the appropriate content filter. The filter extracts text chunks from the document and passes them to Index Server in a format the system recognizes.
In addition to extracting text chunks, another important function of the content filter is to recognize language shifts in documents. Some document formats indicate the language used for a particular chunk of text. If these tags exist, the content filter emits the tag with its corresponding text chunk. For example, the filter may emit a chunk of text that corresponds to a paragraph written in French. This chunk of text will be tagged by the filter as "French." Index Server uses the language tag to load the appropriate word breaker and normalizer for the language (see below).
Content filters are also responsible for handling embedded objects. When an embedded object is encountered in a document, its type is identified and the appropriate filter is activated. This means that Index Server will index not only the text in a Word document, but also any text in a Microsoft Excel spreadsheet that is embedded in the Word document.
Since there are thousands of different programs and data formats, and since document formats frequently change, the programmatic interface used to implement content filters has been abstracted by creating the open standard IFilter Interface. This is a contract between the Index Server and the rest of the world that specifies how content filters will be used. This allows other companies to write content filters for their data. It also means that those most familiar with the data format are the ones to write the content filter for that format.
After filtering, the next major task is word breaking.
Filters emit streams of characters. Because Index Server indexes words, it must be able to identify the words within the character stream. It is easy for people to look at a sequence of characters and identify words but this is a difficult task for a computer. Different languages treat words and the breaks between words very differently. Many languages use white space and punctuation to indicate word breaks. Other languages, such as Japanese, don't use white space to indicate word breaks.
Even some European languages present breaking problems. Compound verbs in German, for example, are usually split into two parts when they are inflected, with one part appearing near the beginning of a sentence and the other part at the end. Simple white space-based breaking doesn't work very well with German. The German word breaker has to look for sentences and examine them one at a time to find out where these inflected forms of the verbs are and then un-inflect them to find the base form.
Index Server provides language-specific word breakers which understand how to break a stream of characters into valid words. These modules understand a particular language's structure and syntax, and they analyze the text to identify words. Index Server provides word breakers for the following languages:
Word breakers accept a stream of characters on one side and emit words out the other. To avoid problems with code pages and other double-byte character-set issues, Index Server uses Unicode to store all its index data.
When a language is identified, a word breaker is loaded up for that language. In the case of a stream of English text, for example, the English word breaker will be used, and it will do things like look for punctuation and white spaces.
Like content filters, word breakers (and normalizers) are modular components. Independent software vendors can create their own word breakers using the open standard, and plug them into the system. This allows third parties to provide linguistic utilities for languages not currently supported by Index Server.
The final stage of indexing is text normalizing. Normalizing "cleans up" the words emitted by the word breaker and handles things like capitalization, punctuation and "noise" word removal. Normalizing allows uniform representation of the words once they're put into the index.
In most languages, written text contains a number of noise words—words which smooth the structure of a sentence but have little meaning independent of context. English examples include "the", "of", "and" "you", and there are several hundred similar words. These words are important to the language as far as structure and grammar go, but they have very little content information associated with them.
References to these words are not stored in the content index. The system maintains a system-wide list of noise words on a per-language basis which can be customized by the administrator. When one of these noise words is produced while a document is being filtered, the noise word is ignored.
Noise word removal can significantly reduce the size of the index since they constitute the bulk of written text. A list of about 100 English noise words represents approximately 50% of all English text. Noise-word lists can be customized by the user to account for local slang and application-specific words.
Once words are normalized, they are put into the content index.