A data repository (DR) is a relational picture of the data residing in the organization's on-line transaction processing (OLTP) systems. There are a number of benefits from operating DSS applications against a data repository:
The data repository should contain two layers. Each layer may contain any number of tables. Physically, each layer can reside on any number of servers including the OLTP servers. In practice, it usually makes the most sense to dedicate a SQL Server, separate from the OLTP server, and store both layers on this new server.
The new data repository doesn't have to be created all at once. Instead, the data repository requirements for the next 3-5 years should be designed and the data repository should evolve, driven by the prioritized needs of the end-user applications.
The data repository should contain proper primary and foreign key relationships. SQL is not as powerful when operating against non-relational data. Do it right!
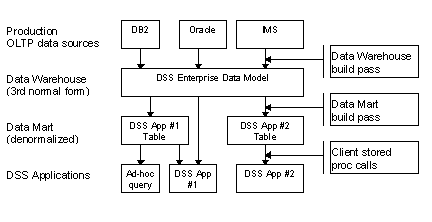
Data Repository Model
The data warehouse layer contains a normalized picture of the enterprises data for a given period of time. It is called the data warehouse because, like a wholesaler, it provided data in bulk to other services and not the end user.
It contains consolidated business entities, and is not tuned for specific end-user applications. It should be refreshed in batch at regular intervals. Since the data may come from many different sources, the data warehouse build pass should rigorously convert the data to a consistent enterprise-wide view. This may involve intensive normalization and validation of denormalized data.
The data warehouse build pass will be specific to your environment. Often specialized gateway products (e.g. SNA Server or MDI Gateway) or custom server-based applications are required to migrate data from legacy production environments to SQL Server.
SQL Server version 6.0 supports two key pieces of functionality to support this batch process. The replication server will migrate production data automatically at regular intervals from certain data sources. And SQL Scheduler and stored procedure cursor support will enable complicated data migration to occur all within the context of SQL Server, without the need to build custom Windows NT services in C.
The data mart is built from the data warehouse in a second batch pass. The data marts are designed for specific end-user applications—often they are designed as a single table "one-stop shopping" client data source. It is called a data mart because, like a retailer, it provides data packaged the way the end user would like to see it.
For example, where an application request for data might involve a four-table join against the data warehouse, it might only involve a single data mart table.
All end-user and DSS application access to the data repository should be in the form of stored procedures, which must be approved and tested by the DBA. This will prevent runaway queries on the server. More on this later.
Since the data warehouse and data mart are both built in SQL Server, the data mart can be refreshed from the data warehouse with SQL Server stored procedures invoked at regular intervals.