To perform speech recognition, an application needs an audio-source object to provide speech input, an engine object to process the speech, and a grammar object to provide the engine with the lists of words or rules that determine what the engine can recognize. As an alternative to creating its own engine object and audio-source object, an application can use a speech-recognition sharing object to use an engine and an audio source that are shared with other applications.
An application can use the speech-recognition enumerator and engine enumerator to locate a speech-recognition mode and create an engine object. As soon as the application has the engines it needs, it can release these objects.
If the engine provides a speech-recognition results object, an application can use this object to analyze a recognition, reevaluate or correct the result, or show feedback to the user.
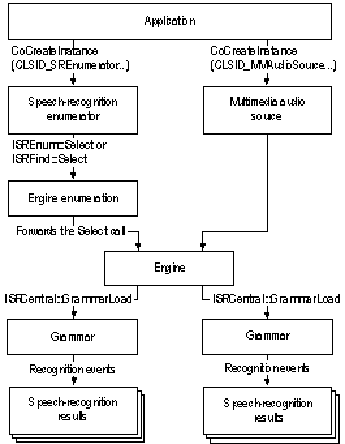
The following illustration shows the sequence in which an application typically creates speech-recognition objects. The illustration includes the names of the interfaces and member functions used to create the objects the interfaces and member functions are described in subsequent sections of this section.
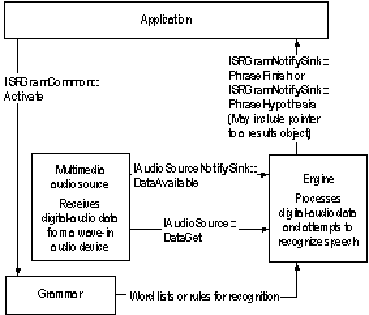
After the application has created the necessary objects, it can use them to recognize speech. The following illustration shows how the application interacts with the engine, grammar, and audio-source objects to recognize a phrase.