Text-to-speech objects provide fairly detailed control of text-to-speech. Together, these objects serve as a translation layer for an application, allowing it to use any of the text-to-speech engines available on the system and to send text as audio data to multimedia wave-out devices or other audio destinations. There are the following text-to-speech objects:
· The engine enumerator enumerates the text-to-speech modes for a particular engine. This object is supplied by the engine vendor.
· The text-to-speech enumerator enumerates the text-to-speech modes for all engines available to the application. This object is supplied by Microsoft.
· The engine object provides a text-to-speech mode for the application to use. This object is supplied by the engine vendor.
· The multimedia audio-destination object represents an audio destination and is based on a multimedia device driver. This object is supplied by Microsoft.
To perform text-to-speech translation, an application needs an engine object to convert the text into speech and a multimedia audio-destination object to play speech output.
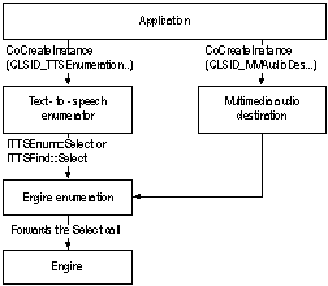
The sole purpose of the text-to-speech enumerator and engine enumerator is to locate a text-to-speech mode and create an engine object. As soon as the application has the engines it needs, it can release the objects.
The following illustration shows the sequence in which text-to-speech objects are typically created and gives the instructions used to create them.
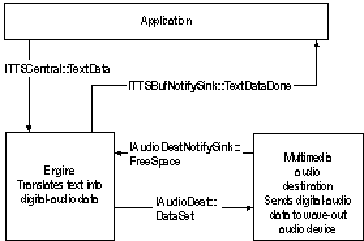
After an application has created the objects it needs, it can use them to play text as speech. When the text-to-speech engine receives text from the application, the engine subdivides the text into buffers and processes one buffer at a time.
The following illustration shows how an application interacts with the engine and audio-destination objects to play a buffer of text.