Fred Pace
MSDN Content Development Group
September 1997
Updated: February 2, 1998
Update details The HelpDesk object model code was revised during development to meet the changing needs of the project. The source code now available with this article accurately reflects the object model for the final HelpDesk sample application. (For example, ExecBoolean() has been renamed ExecQuery()).
Click to copy the HelpDeskOM sample files.
Designing transaction-processing object models is a task that should never be taken on without proper planning. If you have read any of my articles in the past, you know that I am always preaching the "spend time on your design" mantra. In this article, I will take you through the design of a transaction-processing object model for the MSDN HelpDesk Site sample. (For an introduction to the HelpDesk Site sample, see Robert Coleridge's article "The HelpDesk Site Sample: Overview of an Automated Solution.") Along the way, I hope to impart to you some design and development techniques that will be helpful in your own client/server development pursuits. In particular, I'd like to illustrate generic components and how to plan an object model with Microsoft® Transaction Server (MTS) in mind.
Included with this article is HelpDeskOM, the HelpDesk sample object model and source code. To work with these objects you will need the Microsoft Windows NT® 4.0 or Windows® 95 operating system, the Microsoft Visual Basic® version 5.0 programming system, and ActiveX™ Data Objects (ADO) version 1.1 or higher. ADO can be found on the Microsoft Web site at http://www.microsoft.com/ado/.
It is sometimes said that the best programmers are lazy programmers. To protect my reputation I won't say whether that statement fits me or not. I will say that I am a big believer in reusing code. In fact, large portions of code in most of the applications that we build here in MSDN are cut and pasted from other applications. All the transaction-processing applications that have been built in my tenure at MSDN have included two basic components. If any of you have ever read my article, "Designing Intelligent Control Palettes in Visual Basic 5.0," then you already know what code I'm talking about: the data access services, ExecFillArray() and ExecBoolean(), which we have renamed ExecQuery().These data-access services essentially provide functionality in which data can be written to and extracted from a particular type of a database.
In my construction of the HelpDesk object model, it dawned on me that I could have saved myself even more time if I didn't have to cut and paste the code in at all. If I could compile those two methods into a Component Object Model (COM) dynamic-link library (DLL), then I could just reference them in all future applications that need to operate on a Microsoft SQL Server™ database. Does this sound pretty simple? Well, maybe it is—as long as you have thought it all the way through. Let's examine a few issues.
First of all, ExecQuery() and ExecFillArray() are stateful and require that a constant variable, scConnect, is defined so that the methods know data-source and connection information. Since stateful methods can degrade performance and scalability (you'll find out why later in this article), these methods need to be made stateless. This can be done simply by adding a parameter to each method. For example, the original ExecQuery() declaration, ExecQuery(ByVal sQry as String), becomes ExecQuery(ByVal sConnect as String, ByVal sQry as String). By including the sConnect parameter for the data-source connection information, the function now can be passed everything it needs to operate independently. Now that the methods are stateless, they can be encapsulated into a component (that is, a Visual Basic class file) and compiled. As you'll see later in this article, when planning a design that will operate within the Microsoft Transaction Server environment, stateless methods are the only way to go.
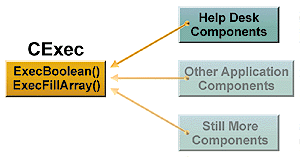
Now let's consider the advantages and ramifications of this data-access component. Let's first respond to all the folks who think that I just killed their data-access performance by removing the data-access methods from a more monolithic code base. Have I really? After all, the new component (CExec) is compiled into an ActiveX DLL (DBExec.DLL) and will be executed in-process, dramatically reducing (if not eliminating) any possible performance penalty. Now let's look at what I have gained: a component—which any other component can reference—that can perform data-access services on any SQL Server database (Figure 1).
Figure 1. Centralized data access
This component centralizes all SQL Server connections—data access is done through the component rather than through random connections to SQL Server. It can also be integrated into Microsoft Transaction Server should scalability become an issue. I've also gained an easily maintainable code base. Since the code isn't pasted into several different transaction processing objects, if I ever need to make a change (such as MTS transaction semantics), I can easily locate the code. Does the gain outweigh the cost? I would have to say yes.
Microsoft Transaction Server brings a wealth of scalability features to the mix, including object-instance management, transaction monitoring, and resource management (connections and threads). If you are building something that could potentially be rolled out to numerous clients, you should investigate the MTS offerings. Let's discuss two of the most important aspects of components that run under MTS—they're stateless and they're specific in functionality.
As I mentioned earlier in this article, stateless components are fully encapsulated, self-sufficient pieces of functionality. That is, they don't require any bits of global data in order to get their work done. As I explained with the ExecQuery() and ExecFillArray() methods, when a stateless method is called, everything that is required for that method to do its work is included in the method parameter list. Let's find out why this is so important.
Microsoft Transaction Server has the ability to share a component among several different clients by using techniques known as just-in-time (JIT) object activation and as-soon-as-possible (ASAP) deactivation. These abilities allow MTS to enable and sustain component references for as long as they are in use by the client. Notice that I said "in use" rather than "referenced by." MTS may shuffle a single instance of a component among several different clients, each with references. If MTS has to manage a component's stateful data, the component can't be efficiently deactivated and shared. Because of this, stateless components are a necessity.
The following code illustrates a simplified look at one of the HelpDesk components, CTrans, that is designed to be operated from within MTS. Notice that the class declaration includes no globally modifiable (stateful) data. Each method requires (as parameters) all the data that is required for it to do its job.
Option Explicit
Private Const scConnect = "helpdesk"
Public Function ClaimRequest(lTechId As Long, lReqId As Long) As Boolean
. . .
Public Function GetDomain(iDomain As icHDDomains, sData() As String) As Boolean
. . .
Public Function GetRequest(lReqId As Long, sData() As String) As Boolean
. . .
The objects that interact directly with a user interface do not need to be managed by MTS as they sit directly on the client machine. The following code illustrates the header of a stateful client-side component, CAdmin:
Option Explicit
. . .
Private m_cLocs As Collection
Private m_cReqs As Collection
Private m_cSkills As Collection
Private m_cTechs As Collection
Private m_lTechId As Long
. . .
Notice all the variables prefaced with an m_. These are module-level variables that store stateful data that is shared among the component's methods. This component should never be operated from within MTS.
Figure 2 illustrates the components of HelpDesk that are designed to be managed by MTS.
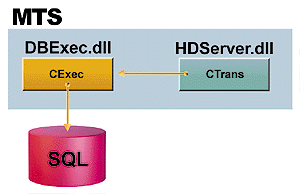
Figure 2. MTS-designed components
A transaction that performs a single task is said to be granular. (Within the four-tier architectural model used by HelpDesk, a granular transaction can also be considered a business rule. For a description of the HelpDesk's adaptation of the four-tier model, see "The HelpDesk Site Sample: Overview of an Automated Solution.") For example, placing an order is generally not considered to be a granular unit of work. Placing an order generally consists of checking availability, decrementing inventory, incrementing (if needed) back orders, and so on. Each of these transactions may in turn need to be broken down further. Transactions should be made as granular as possible (while maintaining acceptable performance) and then encapsulated within workflow methods. The HelpDesk object model doesn't currently require any multistep workflow (but the design is in place should the need arise), so I'll have to demonstrate this with the order-processing example. ProcessOrder() would be a workflow method that encapsulates the granular transactions required to actually process the order. The encapsulated workflow method may look something like the following:
Public Sub ProcessOrder
CheckAvailability()
If DecrementInventory() Then
'Do more stuff
Else
IncrementBackOrder()
End If
End Sub
Creating granular transactions improves both scalability and code reuse. Consider the ProcessOrder() example again. Since the transactional code has been isolated into granular business rules, those rules can be executed across several machines if necessary. Also, the business rules can easily be reused in other workflow methods if necessary. Had ProcessOrder() been written as a monolithic, single-function piece of code, neither of these benefits could be realized.
HelpDesk is designed with granularity in mind. Transactions are designed as single-function stored procedures in the SQL database and then wrapped by business methods in Visual Basic. These business methods are in turn encapsulated by workflow methods.
Okay, so what does the whole enchilada look like? Figure 3 depicts the HelpDesk sample object model.
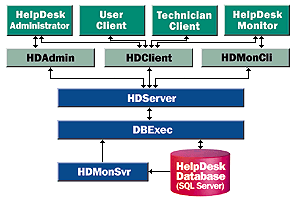
Figure 3. The HelpDesk object model
As you can see, on the server side of this diagram two physical components exist, DBExec and HDServer. The client side has one component, HDClient.
DBExec contains the data-access services that I described earlier in this article. This component is generic, has no specific knowledge of the HelpDesk SQL database, and is capable of interacting with any SQL Server database. DBExec is used by the component in HDServer.
HDServer contains HelpDesk business methods and its functionality is specific to the needs of the HelpDesk sample. This DLL provides the CTrans component, which supports the client-side components in HDClient. Table 1 is a partial list of the methods of CTrans. For a complete list, see the "HelpDesk API Reference".
Table 1. CTrans Methods
| ClaimRequest | Marks a specified request as claimed by a specified technician |
| GetDomain | Gets a domain from the database |
| GetRequest | Gets a specified request |
| GetRequests | Gets a collection of all requests for a specified technician |
| GetReqDetail | Gets the details of a specified request detail record |
| GetReqDetails | Gets all the request details for a specified request |
| GetTech | Gets a specified technician |
| GetTechs | Gets all specified technicians |
| ReAssignReq | Reassigns a request from one technician to another |
| ResolveRequest | Sets a specified request as resolved |
| UnclaimRequest | Unclaims a previously claimed request |
| WorkRequest | Tags a request as work in progress |
The client-side DLL, HDClient, provides the administrative object (CAdmin) and three data objects (CReqDetail, CRequest, CTech), as well as workflow to client interfaces. Its functionality is specific to the needs of the sample HelpDesk user interfaces. Table 2 is a partial list of the methods of CAdmin. For a complete list, see the "HelpDesk API Reference".
Table 2. CAdmin Methods
| Init | Initializes the administrative object |
| FillListLocs | Returns a list of locations |
| FillListSkills | Returns a list of skills |
| FillListReqs | Returns a list of requests |
| FillListTechs | Returns a list of technicians |
| GetNewReq | Obtains a new CRequest object |
| GetNewReqDet | Obtains a new CReqDet object |
| GetNewTech | Obtains a new CTech object |
| GetTechByAlias | Returns a technician object by e-mail alias |
| ReAssignReq | Reassigns a specified request |
| ResolveRequest | Resolves a request |
| UnclaimRequest | Unclaims a previously claimed request |
| WorkRequest | Flags a request as work in progress |
| Term | Called to terminate usage of object |
| ClaimRequest | Claims a request for resolution |
After spending some time on the HelpDesk object model's architecture, the actual implementation was really pretty straightforward. The only noteworthy functionality is the means by which rows of data are moved between components, particularly between the client machine and the server machines.
To efficiently move sets of data, I chose to implement data packaging. When a data set is requested by the client, the request is handled by the ExecFillArray() method in the DBExec.dll. ExecFillArray() executes a SQL Server stored procedure that returns a cursor. ExecFillArray() then walks the cursor and fills an array with the cursor data. Moving sets of data around as an array is much more efficient than moving around collections of objects or recordsets. However, because of the complexities of working with arrays and offsets, they aren't exactly the friendliest data structure to present to clients. Enter the data packager . . .
The array is passed to the client-side component and processed by a data packager. The packager's mission in life is to take an array of data and turn it into a easy-to-use collection of data objects. The following is the packager code for Technician data:
Public Sub FillListTechs()
. . .
Dim sData() As String
On Error Resume Next
Set oTrans = New HDServer.CTrans
Set m_cLocs = Nothing
If oTrans.GetTechs(icWorkingTechs, sData) Then
For iIndex = LBound(sData, 2) To UBound(sData, 2)
Set oTech = New CTech
With oTech
.Admin = Me
.PKId = CLng(sData(icTechPkId, iIndex))
.SkillId = CLng(sData(icTechSkillId, iIndex))
.LocationId = CLng(sData(icTechLocId, iIndex))
End With
m_cLocs.Add oTech, "Id=" & CStr(oTech.PKId)
Next iIndex
End If
Set oTrans = Nothing
End Sub
Now, the developer can work with neat collections of data objects instead of arrays and offsets that are more prone to errors. If you want to read more about packager interfaces and other useful server interface techniques, be sure to check out Ken Bergmann's excellent article, "Three Useful Server Interface Techniques."
Well, now you should have a pretty good idea of how the HelpDesk object model works. Hopefully, you have also garnered some useful insights that will help you in your multitiered client/server development. If I leave you with anything at all, I hope that it is with an understanding of how important it is to spend time on your design and architecture up front. Too often, developers dive into coding a project without having a proper architecture. Unfortunately, this only becomes apparent when their application won't scale or easily adapt to some unforeseen business needs.
The MSDN Library is full of articles that can be of tremendous benefit when architecting a client/server system. Along with the articles I've already mentioned, check out Ken Bergmann's fantastic Client/Server Solutions series of articles starting with "Client/Server Solutions: The Architecture Process." Also, Steve Kirk's article "Task Distribution in a Customer Service System" covers task distribution in the HelpDesk Site sample. So be sure to check it out as well. Read and practice, folks. Read through sample code and study designs. Perhaps you can improve on the techniques used. You'll never know until you try.