Table 30 supports the investigation of item bias, Differential Item Functioning (DIF), i.e., interactions between individual items and types of persons. Specify DIF= for person classifying indicators in person labels. Item bias and DIF are the same thing.
In Table 30.1 - the hypothesis is "this item has the same difficulty for two groups"
In Table 30.2, 30.3 - the hypothesis is "this item has the same difficulty as its average difficulty for all groups"
In Table 30.4 - the hypothesis is "this item has no overall DIF across all groups"
Example output:
You want to examine item bias (DIF) between Females and Males in Exam1.txt. You need a column in your Winsteps person label that has two (or more) demographic codes, say "F" for female and "M" for male (or "0" and "1" if you like dummy variables) in column 9.
Table 30.1 is best for pairwise comparisons, e.g., Females vs. Males. Use Table 30.1 if you have two classes.
Table 30.2 or Table 30.3 are best for multiple comparisons, e.g., regions against the national average. Table 30.2 sorts by class then item. Table 30.3 sorts by item then class.
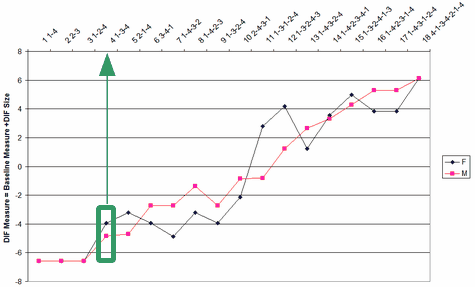
This displays a list of the local difficulty/ability estimates underlying the paired DIF analysis. These can be plotted directly from the Plots menu.
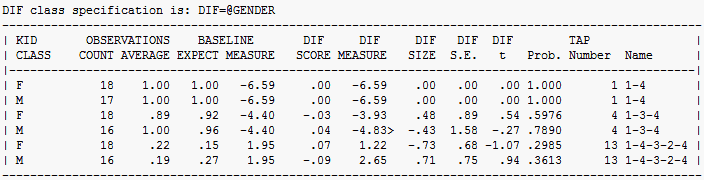
DIF class specification identifies the columns containing DIF classifications, with DIF= set to @GENDER using the selection rules.
The DIF effects are shown ordered by CLASS within item (column of the data matrix).
KID CLASS identifies the CLASS of persons. KID is specified with PERSON=, e.g., the first CLASS is "F"
OBSERVATIONS are what are seen in the data
COUNT is the number of observations of the classification used for DIF estimation, e.g., 18 F persons responded to TAP item 1.
AVERAGE is the average observation on the classification, e.g., 0.89 is the proprtion-correct-value of item 4 for F persons.
COUNT * AVERAGE = total score of person class on the item
BASELINE is the prediction without DIF
EXPECT is the expected value of the average observation when there is no DIF, e.g., 0.92 is the expected proprtion-correct-value for F without DIF.
MEASURE is the what the overall measure would be without DIF, e.g., -4.40 is the overall item difficulty of item 4 as reported in Table 14.
DIF: Differential Item Functioning
DIF SCORE is the difference between the observed and the expected average observations, e.g., 0.92 - 0.89= -0.03
DIF MEASURE is the item difficulty for this class, e.g., item 4 has a local difficulty of -3.93 for CLASS F.
The average of DIF measures across CLASS for an item is not the BASELINE MEASURE because score-to-measure conversion is non-linear. ">" (maximum score), "<" (minimum score) indicate measures corresponding to extreme scores.
DIF SIZE is the difference between the DIF MEASURE for this class and the BASELINE DIFFICULTY, i.e., -3.93 - -4.40 = .48. Item 4 is .48 logits more difficult for class F than expected.
DIF S.E. is the approximate standard error of the difference, e.g., 0.89 logits
DIF t is an approximate Student's t-statistic test, estimated as DIF SIZE divided by the DIF S.E. with a little less than (COUNT-2) degrees of freedom.
Prob. is the probability of the t-value. This is approximate because of dependencies between the statistics underlying the computation.
These numbers are plotted in the DIF plot. Here item 4 is shown. The y-axis is the "DIF Measure".