Winsteps chooses the model-family based on MODELS=
Models=R (or MODELS= is omitted) is the rating-scale family of models which includes the Andrich Rating-Scale Model, the Masters Partial-Credit Model, the Grouped Rating-Scale Model and the Rasch Dichotomous Model.
Within Models=R, the choice of model is decided by isgroups=
If ISGROUPS= is omitted, then
1) If there are only two categories in the data the dichotomous model
2) If there are more than two categories the Andrich Rating-Scale Model
ISGROUPS= *file name |
file containing details |
ISGROUPS = * |
in-line list |
ISGROUPS = codes |
codes for item groups |
If ISGROUPS=0 then
the Masters Partial Credit Model
If ISGROUPS=(something else)
the Grouped Rating-Scale Model
Please look at the output in Table 3.2, 3.3, .... to see exactly how the data have been modeled.
Items in the same "grouping" share the same dichotomous, rating scale or partial credit response structure. For tests comprising only dichotomous items, or for tests in which all items share the same rating (or partial credit) scale definition, all items belong to one grouping, i.e., they accord with the simple dichotomous Rasch model or the Andrich "Rating Scale" model. For tests using the "Masters' Partial Credit" model, each item comprises its own grouping (dichotomous or polytomous). For tests in which some items share one polytomous response-structure definition, and other items another response-structure definition, there can be two or more item groupings. Groups are called "blocks" in the PARSCALE software.
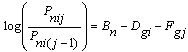
where P is a probability, and the Rasch parameters are Bn, the ability of person, Dgi, the difficulty of item i of grouping g, and Fgj, the Rasch-Andrich threshold between categories j-1 and j of grouping g. If there is only one grouping, this is the Andrich "rating scale" model. If each item forms a grouping of its own, i.e., g=i, this is the Masters' "partial credit' model. When several items share the rating scale, then this could be called an item-grouping-level Andrich rating-scale model, or an item-grouping-level Masters' partial-credit model. They are the same thing.
ISGROUPS= also acts as IREFER=, when IVALUE= is specified, but IREFER= is omitted.
ISGROUPS= has three forms: ISGROUPS=1101110 and ISGROUPS=* list * and ISGROUPS=*filename
ISGROUPS=" " |
(standard if only one model specified with MODELS=) All items belong to one grouping. This is sometimes called "Andrich's Rating Scale Model" |
ISGROUPS=0 |
(standard if MODELS= specifies multiple models) Each item has a grouping of its own, so that a different response structure is defined for each item, as in the "Masters' Partial Credit model". This is also used for rank order data. |
ISGROUPS= some combination of numbers and letters |
Use only one letter or number per grouping, regardless of the XWIDE= setting. Valid are: 0's, 1's, 2's, A's, B's, etc. ("a" is the same as "A"), also #, @, !,& etc. Items are assigned to the grouping label whose location in the ISGROUPS= string matches the item sequence number. Each item assigned to grouping 0 is allocated to a "partial credit" grouping by itself. Items in groupings labeled "1", "2", "A", etc. share the response-structure definition with other items in the same labeled grouping. |
Valid one-character ISGROUPS= codes include: !#$%&-./123456789<>@ABCDEFGHIJKLMNOPQRSTUVWXYZ^_|~
A-Z are the same as a-z.
For the ISGROUPS= specification, "0" has the special meaning: "this is a one item grouping" - and can be used for every 1 item grouping.
Characters with ASCII codes from 129-255 can also be used, but display peculiarly: ÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâã etc.
When XWIDE=2 or more, then
either (a) Use one character per XWIDE= and blanks,
NI=8
XWIDE=2
ISGROUPS=' 1 0 1 0 1 0 1 1'
or (b) Use one character per item with no blanks
NI=8
XWIDE=2
ISGROUPS='10101011'
ISGROUPS=*
item number grouping code
item number-item number grouping code
*
Each line has an item number, e.g., 23, or an item number range, e.g., 24-35, followed by a space and then a grouping code, e.g., 3. The items can be out of order. If an item is listed twice, the last entry dominates.
ISGROUPS=*file name
This has a file with the format of the ISGROUPS=* list.
Particularly with ISGROUPS=0, some extreme categories may only be observed for persons extreme scores. To reinstate them into the measurement analysis, see Extreme Categories: Rescuing the Dropped.
Groupings vs. Separate Analyses
ISGROUPS= is very flexible for analyzing together different item response structures in one analysis. Suppose that an attitude survey has 20 Yes-No items , followed by 20 5-category Likert (Strongly disagree - disagree - neutral - agree- strongly agree) items, followed by 20 3-category frequency (never - sometimes - often) items. When possible, we analyze these together using ISGROUPS=. But sometimes the measurement characteristics are too different. When this happens, the fit statistics stratify by item type: so that, say, all the Yes-No items overfit, and all the Frequency items underfit. Then analyze the test in 3 pieces, and equate them together - usually into the measurement framework of the response structure that is easiest to explain. In this case, the Yes-No framework, because probabilistic interpretation of polytomous logits is always difficult to explain or perform.
The "equation" would be done by cross-plotting the person measures for different item types, and getting the slope and intercept of the conversion from that. Drop out of the "equation" any noticeably off-trend-line measures. These are person exhibiting differential performance on the different item types.
Example 1: Responses to all items are on the same 4-point rating scale, an Andrich "Rating Scale" model,
ISGROUPS=" "
Example 2: An arithmetic test in which partial credit is given for an intermediate level of success on some items. There is no reason to assert that the intermediate level is equivalent for all items. 0=No success, 1=Intermediate success (or complete success on items with no intermediate level), 2=Complete success on intermediate level items.
CODES=012 valid codes
ISGROUPS=0 each item has own response structure, i.e., Masters' Partial Credit model
or
ISGROUPS=*
1 0 ; item 1 is in Grouping 0, no other items mentioned, so all assumed to be in Grouping 0
*
Example 3: An attitude survey consists of four questions on a 0,1,2 rating scale (grouping 1), an Andrich "Rating Scale" model, followed by three 0,1 items (grouping 2), an other Andrich "Rating Scale" model, and ends with one 0,1,2,3,4,5 question (grouped by itself, 0), a Masters' "Partial Credit" model.
NI=8 number of items
CODES=012345 valid codes for all items
ISGROUPS=11112220 the item groupings
or
ISGROUPS=*
1-4 1
5-7 2
8 0 ; this line is optional, 0 is the standard.
*
When XWIDE=2, use two columns for each ISGROUPS= code. Each ISGROUPS= code must be one character, a letter or number, specified once in the two columns, e.g. " 1" or "1 " mean "1", and " 0" or "0 " mean "0".
Example 4: You wish most items on the "Liking for Science" Survey to share the same rating scale, an Andrich "Rating Scale" model, (in Grouping A). Items about birds (1, 10, 21) are to share a separate response structure, another Andrich "Rating Scale" model, (in Grouping B). Items 5 (cans) and 18 (picnic) each has its own response structure, i.e., the "Masters' Partial Credit" model, (Grouping 0).
NI=25 number of items
XWIDE=2
CODES=000102 valid codes for all items
ISGROUPS=' B A A A 0 A A A A B A A A A A A A 0 A A B A A A A'
item groupings - use only one letter/number codes.
or
ISGROUPS=* ; XWIDE=2 is not a worry here, but use one letter/number codes.
1-25 A ; most items in grouping A
1 B ; item 1 transferred to grouping B
10 B
21 B
5 0 ; grouping 0 means item is by itself
18 0
*
Example 5: Four separate tests of patient performance (some on a 4-point rating scale, some on a 5-point rating scale) are to be Rasch-analyzed. All 500 persons were given all 4 tests. I analyzed each separately, to get an idea of good-fitting and bad-fitting items, etc. Now, I'd like to run all 4 tests together using a partial credit model.
There is no problem running all four tests together. Put them all in one file, or use MFORMS=. If you intend every item of every test to have its own rating scale (i.e., a strict partial-credit model), use ISGROUPS=0. But if you intend items on test 1 to share the same rating scale, similarly test 2 etc. (i.e., a test-level partial-credit model), then specify ISGROUPS=111111112222233334444.... matching the grouping number indicators to the count of items in each test.
Example 6: Items are to be rescored in 3 different ways, and then the items are to be divided into 4 rating scale structures.
ISGROUPS=11112223312444 ; 4 RATING SCALE GROUPINGS
IREFER =AAAABBBCCABBBB ; 3 RECODINGS
CODES =01234 ; ORIGINAL CODES IN DATA
IVALUEA =01234 ; ORIGINAL CODING MAINTAINED - THIS LINE CAN BE OMITTED
IVALUEB =43210 ; CODING IS REVERSED
IVALUEC =*112* ; DICHOTOMIZED WITH EXTREME CATEGORIES MARKED MISSING
Example 7: A five-item test.
Item 1: Dichotomy already scored 0-1 ; let's call this a "D" (for dichotomy) group item
Item 2: Dichotomy already scored 0-1 ; this is another "D" (for dichotomy) group item. Under the Rasch model, all dichotomies have the same response structure.
Item 3: Partial credit polytomy already scored 0-1-2 ; this is an "0" type item. "0" means "this item has its own response structure".
Item 4: Rated polytomy already scored 1-2-3-4 ; let's call this an "R" group items
Item 5: Rated polytomy already scored 1-2-3-4 with the same rating scale as item 4, so this is another "R" group item,
CODES = 01234 ; this is all possible valid codes in the data
ISGROUPS = DD0RR ; Winsteps detects from the data which are the responses for each item-group and what they mean.
Example 8: An attitude survey in which the rating-scale items are worded alternately positively and negatively.
CODES = 12345 ; the rating scale of 5 categories
; rescore the items
IREFER = PNPNPNPNPN ; 10 item, alternately positively-worded and negatively-worded
IVALUEP = 12345 ; the positive orientation
IVALUEN = 54321 ; the negative orientation
; model the rating scales
GROUPS = PNPNPNPNPN ; model the two item orientations with separate rating scale structures
Example 9: A test with 5 dichotomous items and 5 partial credit items:
CODES = 01234 ; all possible item scores
GROUPS = 1111100000 ; 5 dichotomies share the same response structure
Example 10: 3 rating-scales in one instrument.
NAME1 = 1 ; First column of person label in data file
NAMLEN = 14
ITEM1 = 19 ; First column of responses in data file
NI = 57
XWIDE = 1
GROUPS=111111111111111111111111111222222222222222222222222222233
; Group 1 categories 0,1,2,3,4 ; Winsteps discovers this by inspecting the data
; Group 2 categories 0,1,2,3
; Group 3 categories 0,1,2,3,4,5,6
CODES=0123456 ; Valid response codes in the data file
&END
.....
END NAMES ; END NAMES or END LABELS must come at end of list
XX 10001 1 2 2 444444444442434444234444444333332333333333333233133323366
XX 10002 1 2 1 444444444442444344334343334133333333333333333333333333366
XX 10003 1 1 3 4444444440324 4444420234444333333233333333133323333333366
XX 10004 1 2 1 444444444043444444444444444333333333333333333333333333345
XX 10005 1 2 1 443334444431441033113312332233332232303323032332020333243
XX 10006 1 2 1 233334442422323442333333343123332332222323332331233223344