This uses the estimated (or anchored) person, item and structure measures or person-response-string resampling-with-replacement to simulate a data file equivalent to the raw data. This can be used to investigate the stability of measures, distribution of fit statistics and amount of statistical bias. Each time SIFILE= is run, or selected from the Output Files pull-down menu, a simulated data file produced. Do simulated analyses with several simulated datasets to verify their overall pattern.
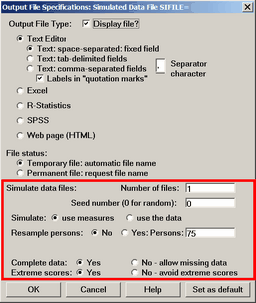
The parts of the dialog box outside the red rectangle are described in Output file specifications. |
|
Simulated data files: |
invoked with SIFILE= |
Number of files: |
SINUMBER=, specifies the number of simulated files to produce. If SINUMBER= is greater than 1, then the data file name is automatically incremented, and so is the SISEED= pre-set seed value |
Seed number (0 for random): |
SISEED=, controls whether the pseudo-random number generator is seeded with the system clock (0 or 1), or with a user-chosen value, (2 and above) |
Simulate: use measures or use the data |
SIMEASURE=, chooses whether the simulated data is generated from the estimated measures (use measure), or by resampling from the observed data (use the data). If you wish to over-ride the estimated measures, then use IAFILE=, PAFILE= and SAFILE= |
Resample persons: No or Yes: Persons |
SIRESAMPLE=, controls whether resampling occurs, and, if it does, how many person records to include in the simulated data file |
Complete data: Yes or No - allow missing data |
SICOMPLETE=, Yes for complete data. No for missing data patterns to be repeated in the simulated data file |
Extreme scores: Yes or No - avoid extreme scores |
SIEXTREME=, Yes to allow the simulated data to include extreme (zero, minimum possible or perfect, maximum possible) scores. No to avoid generating extreme scores (when possible) |
Example 1. It is desired to investigate the stability of the "Liking for Science" measures.
(1) Estimate measures from SF.txt
(2) Choose SIFILE= from the Output Files menu. SIFILE=SFSIMUL.TXT
(3) Rerun Winsteps with DATA=SFSIMUL.TXT on the "Extra Specifications" line.
(4) Compare person, item and structure measures.
The file format matches the input data file if both are in fixed-field format. When SIFILE= is written with CSV=Y, comma-separated or CSV=T, tab-separated, the item responses precede the person label.
Example: KCT.txt simulated with CSV=N fixed field format (resampling response strings):
Dorothy F 111111111100000000 -.2594 13
Elsie F 111101111100000000 -1.3696 14
Thomas M 111111111010000000 -.2594 31
Rick M 111111111010000000 -.2594 27
KCT.txt simulated with comma-separated, CSV=Y, HLINES=Y, QUOTED=Y format (resampling person measures):
"1-4","2-3","1-2-4","1-3-4","2-1-4", ... ,"KID","Measure","Entry"
1,1,1,1,1,1,0,1,1,1,0,0,0,0,0,0,0,0,"Rick M",-.2594,27
1,1,1,1,1,1,1,1,1,0,1,0,0,0,0,0,0,0,"Helen F",-.2594,16
1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,"Rod M",1.9380,28
1,1,1,1,1,1,1,1,1,1,0,0,0,0,0,0,0,0,"William M",.9229,34
Example 2. To estimate the measure standard errors in a linked equating design.
1. Do a concurrent calibration with Winsteps
2. Simulate data files SIFILE= from the Output Files menu.
Specify "complete data" SICOMPLETE= as "No" to maintain the same data pattern.
Save 10 simulated sets, SINUMBER=, as S.txt S2.txt .....
3. Rerun your Winsteps analysis 10 times
Specify in Extra Specifications "DATA=S.txt PFILE=P1.txt CSV=TAB" etc.
This will produce 10 PFILE=s. Export them in Excel format.
4. Use Excel to compute the standard deviation of the measures for each person based on the 10 person measures
5. These are the model standard errors for the equating design for the measures.
6. Inflate these values by 20%, say, to allow for systematic equating errors, misfit, etc.
Example 3. If you do need estimation-bias-correction (STBIAS=) that is as accurate as possible with your data set, you will need to discover the amount of bias in the estimates and correct for it:
1. In your control file, STBIAS=No and USCALE=1
2. Obtain the Winsteps estimates for your data
3. Simulate many datasets using those estimates. (SIFILE= on the Winsteps Output Files menu).
4. Obtain the Winsteps estimates from the simulated data sets
5. Regress the simulated estimates on your initial estimates. These will give a slope near 1.0.
6. Obtain the Winsteps estimates for your data with USCALE = 1/slope. The set of estimates in 6 is effectively unbiased.
Example 4. You need to simulate data from generating values. You can use Winsteps to simulate a dataset.
1. Obtain the generating item difficulties, person abilities and threshold values. If you need a normal distribution of person abilities, you can generate this with Excel.
a. From your standard analysis, output IFILE=if.txt, SFILE=sf.txt
b. Use Excel or similar to simulate a normal distribution of person abilities with the mean and S.D. that you want.
In Excel:
Cell A1 = Mean
Cell B1 = S.D.
Cell A2 = =ROW()-1
Cell B2 = =NORMINV(RAND(),$A$1,$B$1)
then copy A2, B2 for as many rows as you want the sample size.
c. Copy Columns A and B into a text file, pf.txt. Delete row 1.
d. In your Winsteps control file:
IAFILE=if.txt
SAFILE=sf.txt
PAFILE = pf.txt
SIFILE= simulated.txt
2. Construct a Winsteps control file including the generating values in IAFILE=, PAFILE=, SAFILE=
3. Make a rectangular dataset with a row of valid responses (can be the same one) as wide as the number of items
and with a column of valid responses (can be the same one) as long as the number of persons, e,g,
number of persons = 7
number of items =10
the artificial dataset can be:
1111111111 ; 10 items across
1
1
1
1
1
1 ; 7 person rows
4. Run Winsteps. Choose SIFILE= option from the output files menu. Click on "complete data" to simulate the entire data matrix.
Example 5. Multiple simulations in Batch mode. See BATCH=
These can construct bootstrap confidence intervals for DIF estimates, etc.
Set up 100 simulations in a batch file, and extract the relevant numbers from the 100 output DIF tables.
PowerGREP is great software for extracting values from files. For instance:
To pick out lines 10-35 in the output files (after line 9, for 26 lines):
Action type: Search
File sectioning: Search and collect sections
Section search: \A([^\r\n]*+\r\n){9}(([^\r\n]*+\r\n){0,26})
Section collect: \2
Search: the search string: .* for everything
Performing multiple simulations in Batch mode
1. Use NotePad to create a text file called "Simulate.bat"
2. In this file:
REM - produce the generating values: this example uses example0.txt:
START /WAIT c:\winsteps\WINSTEPS BATCH=YES example0.txt example0.out.txt PFILE=pf.txt IFILE=if.txt SFILE=sf.txt
REM - initialize the loop counter
set /a test=1
:loop
REM - simulate a dataset - use anchor values to speed up processing (or use SINUMBER= to avoid this step)
START /WAIT c:\winsteps\WINSTEPS BATCH=YES example0.txt example0%loop%.out.txt PAFILE=pf.txt IAFILE=if.txt SAFILE=sf.txt SIFILE=SIFILE%test%.txt SISEED=0
REM - estimate from the simulated dataset
START /WAIT c:\winsteps\WINSTEPS BATCH=YES example0.txt data=SIFILE%test%.txt SIFILE%test%.out.txt pfile=pf%test%.txt ifile=if%test%.txt sfile=sf%test%.txt
REM - do 100 times
set /a test=%test%+1
if not "%test%"=="101" goto loop
3. Save "Simulate.bat", then double-click on it to launch it.
4. The simulate files and their estimates are numbered 1 to 100.
5. The files of estimates can be combined and sorted using MS-DOS commands, e.g.,
Copy if*.txt combinedif.txt
Sort /+(sort column) <combinedif.txt >sortedif.txt